Introduction
Would you like to create a complete, fully configured environment for Continuous Integration / Continuous Delivery with a single request, saving you ton of times in configuring and managing the pipeline? If so keep reading this post, the first one of a series of three where Stefano and I will focus on automation in CloudCenter to align with a DevOps methodology. The entire series is coauthored with Stefano Gioia, a colleague of mine at Cisco. We will be talking about a solution we’ve built on top of Cisco CloudCenter to support CI/CD as a Service.
To keep things simple, we've decided to split the story into
three posts.
• In the first post (this one), we will
introduce the use case of CI/CD as a Service, describing it in detail to show the business and technical benefits.
• The second post will guide you through automating the
deployment of a complete CI/CD environment in few minutes, by implementing a service in the catalog exposed by Cisco CloudCenter.
• In the third post, we will show
how to apply CI/CD to the lifecycle of a sample application.
A little refresh on DevOps
Before taking this journey let’s first clarify what we mean by using the term “DevOps.” DevOps is not a technology or a magic wand that will instantly help you unify the development (Dev) and management (Ops) of your applications.
DevOps encompasses more than just software development.
It's a philosophy of cooperation between different teams in a company, mostly Development (Dev) and Operations (Ops), with the ultimate goal of being more productive and successful in launching new (or updating existing) services to reflect what your customers want.
As shown in the picture below, this is how we see DevOps: as a human brain. We know that the right hemisphere of a human brain is said to be creative, conceptual, holistic: the opposite of the left region, which is rational and analytic.
Apparently, two distinct aspects that cannot always work together. But nature finds a way to allow them to cooperate for the benefit of the human body.
The very same concept can be utilized for your company: your Dev and Ops team has to collaborate to get significant benefits in productivity such as shorter deployment cycles which means increased frequency of software releases and finally better reaction to market and customer needs by quickly deploying new application features.
What about Continuous Integration / Continuous Delivery / Continuous Deployment?
Today Continuous Integration, Delivery and Deployment is a common practice in IT software development.
The central concept is about continuously making small changes to the code, building, testing and delivering more often, more quickly and more efficiently, to able to respond rapidly to changing business contexts.
The picture below illustrates a sample CI/CD process divided into stages:
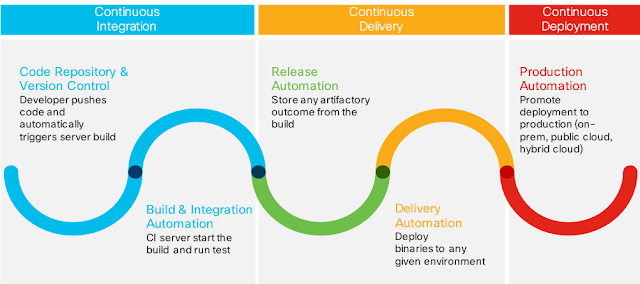 |
| Stages in the CI/CD process |
• Continuous Integration
A common practice of frequently integrating and continuously merging code changes from a team of developers into a shared code repository. Quite often, after new code is committed to a repository, the server triggers a “build” and runs some basic test. Once the application is built and all the tests are passed, it’s time to move to the next step: delivery.
• Continuous Delivery
Simply means delivering the build to a specific target (environment), like Integration Test, Quality Assurance, or Pre-Production.
• Continuous Deployment
Is fundamentally an extension of Delivery (and sometimes it’s included in the Delivery process). It allows you to repeat deployment of your application to production, even many times per day. The production environment could be an on-premises environment or a public cloud. In some advanced scenario, applications can be deployed in a hybrid model, example database on-premise while business logic and front end in a public cloud. This is called a hybrid deployment.
Usually, when defining a CI/CD pipeline you will need at least the following components:
• A code repository to host and manage all your source code
• A build server to build an application from source code
• An integration server/orchestrator to automate the build and run test code
• A repository to store all the binaries and items related to the application
• Tools for automatic configuration and deployment
Let’s take a look at the typical challenges of implementing a CI/CD process.
First of all, having one single CI/CD toolset in your company is not a good option.
 |
| Every LOB uses a different CI/CD toolset |
As you can see from the picture above, every LOB (line of business) might have different requirements (and sometimes also a developer team inside the same LOB) and most likely they will use different technologies to create a new application/business service. They might even use different code language (Java, nodeJS, .Net, etc.) and be more familiar with a specific tool, e.g. GitHub rather than Subversion.
How can you accommodate this diversity?
You probably guessed it right. You can create multiple CI/CD chains and then install multiple tools (perhaps on VM or in a container) depending on the requirements coming from the developers and/or LOB.
However, how much time you will be spending in configuring every time, for each LOB or DevTeam, a new CI/CD chain? Moreover, what about maintaining and upgrading all the components of the CI/CD toolchain to be compliant with any new security requirements from your security department?
How long does it take to prepare, configure, deploy and manage multiple CI/CD chains? Sounds like a typical Shadow IT problem, a phenomenon that happens when a Developer Team or LOB users can’t get a fast-enough response from the IT and rush to a public cloud to get what they need. In that case, the solution was to implement automation and self-service to quickly provides the necessary environment to the end users, with the same speed and flexibility as the public cloud.
Wouldn’t be much easier to adopt the same approach and merely automate the deployment and configuration of the CI/CD chain with a single request generated by a simple HTML form?
Good news: that’s precisely the purpose of “CI/CD as a Service.”
Introducing “CI/CD as a Service”
Let us first clarify an important point: we are not discussing relocating your CI/CD resources and process to the cloud, and then consuming from there. Nor we are discussing the automation task performed by the CI/DP pipeline (push code to the repository, the automatic build of the code, test, and deployment).
What we are proposing here is to automate the deployment and configuration of the tools that are part of your CI/CD Pipeline. With a single request, you will be able to select, create, deploy and configure the tools that are part of your automated CI/CD pipeline.
The key things here is that the customer (a LOB as an example) can decide which are the components that will be part of the CI/CD pipeline. One pipeline could be composed by GitLab, Jenkins, Maven, Artifactory while another one could be composed by SNV,Travis,Nexus.
Your customer will have their own CI/CD chain preconfigured, ready to be used so they can be more productive and focus on what’s matter: create new feature and new applications to sustains your business and competitive advantages.
Let's now have a look at some of the technical and business benefits you can expect if you embrace CI/CD as a Service.
From a technical point of view, here are some good points:
• Adaptable: your LOB/Dev Team can cherry-pick the tools they need it, from your catalog
• Preconfigured: all the components selected, once deployed, are configured to work immediately for you.
• Error-free: as you automated all the steps to deploy and configure the elements, this leaves no room for any human error or misconfiguration
• Clean: always have a clean, stable and up to date environment ready to be used
• Multi-tenant: serving multiple Line of Business (LOB) in your company: each LOB can have his own environment
• Easy Plug: as it’s callable by using REST API, you can easily integrate your IT Service Management system for self-service
• Independent Solution: can run on top of any infrastructure/on-prem private cloud
Don’t stop the business: are you running out of on-premise resources? The solution allows you to quickly deploy the service, temporarily, in a public cloud to avoid blocking the development of your critical project.
The majority of customers are interested in the CI/CD approach, and they are actively looking for a solution that can be easily implemented and maintained; therefore, we firmly believe that a solution for Cisco will be seen as an enabler for their business strategy.
In the
next post, we will present a solution that decouples the tools utilized in CI/CD pipeline from the deployment targets. The Use Case is implemented by Cisco CloudCenter (CCC) a fundamental component of the Cisco Multicloud Solution.
Credits
This post has been authored by
Stefano Gioia, a colleague of mine at Cisco.