Initiatives include being a Gold member of the Openstack Foundation, being in the board of directors, contribute to different projects in Openstack (mainly Neutron, that manages networking, but also Nova and Ironic) with blueprints and code development.
Cisco also uses Openstack in his own data centers, to provide cloud services to the internal IT (our private cloud) and to customers and partners (the Cisco Cloud Services in the Intercloud ecosystem). We also have a managed private cloud offer based on Openstack (formerly named Metacloud).
Based on this experience, a CVD (Cisco Validated Design) has been published to allow customers to deploy the Openstack platform on the Cisco servers and network. The prescriptive documentation guides you to install and configure the hardware and the software in such a way that you get the expected results in terms of scale and security. It's been fully tested and validated in partnership with Red Hat.
Another important point is the offer of the Cisco ACI data model to the open source community. The adoption of such a model in Openstack (the GBP, i.e. the Group Based Policy) is a great satisfaction for us.
Openstack will also be managed by the Stack Designer in Cisco Prime Service Catalog (PSC 11.0), to create PaaS services based on Heat (similarly to what we do now with Stack Designer + UCS Director). Templates to deploy a given Data Center topology will be added as services in the catalog and, based on them, other services could be offered with the deployment of a software stack on top of the Openstack IaaS. The user will be able to order, in a single request, the end to end deployment of a new application.
In this post I will tell you about the main topics in the Cisco-Openstack relationship:
1 - Available Plugins for Cisco products (Nexus switches, UCS servers, ACI, CSR, ASR)
2 - GBP: Group Based Policy (the ACI model adopted by the Openstack community)
Available Plugins for Cisco products
Plugins exist for the following projects in Openstack: Neutron, Nova, Ironic.
You can leverage the features of the Cisco products while you maintain the usual operations with Openstack: the integration of the underlying infrastructure is transparent for the user.
Networking - Project Neutron
Plugins for all the Nexus switching family- Tenant network creation is based on VLAN or VXLAN
Plugins for ACI
- Neutron Networks and Routers are created as usual and the plugin has the role to integrate the API exposed by the Cisco APIC controller
A number of Neutron plugins are available already: Nexus 1000v, 3000, 5000, 6000, 7000 and 9000 Series Switches are supported (see http://www.cisco.com/c/en/us/products/collateral/switches/nexus-3000-series-switches/data_sheet_c78-727737.html).
You can also scale the OpenStack L3 services using the Cisco ASR1K platform (see http://blogs.cisco.com/datacenter/scaling-openstack-l3-using-cisco-asr1k-platform#more-163906) and use the Cloud Services Router (CSR) for Openstack VPN as a Service (see Neutron blueprints web site for Kilo and http://specs.openstack.org/openstack/neutron-specs/specs/kilo/cisco-vpnaas-and-router-integration.html).
Network Service Plug-in Architecture (ML2)
This pluggable architecture has been designed to allow for common API, rapid innovation and vendor differentiation:
Based on the delegation of the real networking service to the underlying infrastructure, the Openstack user does not care what networking devices are used: he only knows what service he needs, and he gets exactly that.
Use the existing Neutron API with APIC and Cisco ACI
When the Openstack user creates the usual constructs (Networks, Subnets, Routers) via Horizon or the Neutron API, the APIC ML2 plugin intercepts the request and send commands to the APIC API.Network profiles, made of End Point Groups and Contracts, are created and pushed to the fabric. Virtual networks created in the OVS virtual switch in KVM are matched to the networks in the physical fabric, so that traffic can flow to and from the external world.

This integration allows you to leverage the single point of management of a UCS domain (up to 160 servers) instead of configuring networking on the single blades or - as in competing server architectures - on the individual switches in the chassis.
An additional advantage offered by UCS servers is the VM-FEX (VM fabric extender) feature: virtual NICs can be offered to the VM directly from the hw, bypassing the virtual switch in the hypervisor thanks to SR-IOV and gaining performances and centralization of the management.
Next picture shows the automated VLAN and VM-FEX Support offered by the Cisco UCS Manager plugin for OpenStack Neutron:

Bare metal deployment - Project Ironic
Plugin for UCS Manager to deploy Service Profiles for bare metal workloads on the UCS bladesIronic is the OpenStack service which provides the capability to provision bare metal servers. The initial version of Ironic pxe_cisco driver adds support to manage power operations of Cisco UCS B/C series servers that are UCSM managed and provides vendor_passthru APIs.
User can control the power operations using pxe_cisco driver. This doesn’t require IPMI protocol to be enabled on the servers as the operations are controlled via Service Profiles.
Code is available in GitHub @ https://github.com/CiscoUcs/Ironic-UCS
GBP: Group Based Policy
The most exciting news is the adoption of the GBP (Group Based Policy) model and API in Neutron, that derives from the way the Cisco APIC controller manages end point groups and contracts in the ACI architecture. A powerful demonstration of the Cisco thought leadership in networking.
The Group Based Policy (GBP) extension introduces a declarative policy driven framework for networking in OpenStack. The GBP abstractions allow application administrators to express their networking requirements using group and policy abstractions, with the specifics of policy enforcement and implementation left to the underlying policy driver. This facilitates clear separation of concerns between the application and the infrastructure administrator.
Two Options for the OpenStack Neutron API
The Neutron user can now select the preferred option between two choices: the usual building blocks in Neutron (Network, Subnet, Router) and the new - optional - building blocks offered by GBP.
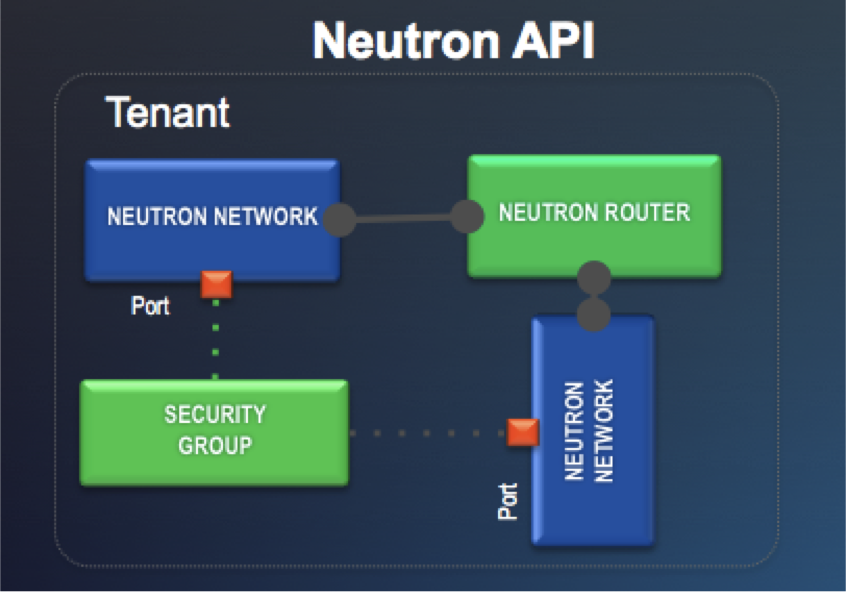
In addition to support for the OpenStack Neutron Modular Layer 2 (ML2) interface, Cisco APIC supports integration with OpenStack using Group-Based Policy (GBP). GBP was created by OpenStack developers to offer declarative abstractions for achieving scalable, intent-based infrastructure automation within OpenStack. It supports a plug-in architecture connecting its policy API to a broad range of open source and vendor solutions, including APIC.
This means that other vendors could provide plugins for their infrastructure, to use with the GBP API.
While GBP is a northbound API for Openstack, the plugins are a southbound implementation.

In this case the Neutron plugin for the APIC controller has a easier task: instead of translating from the legacy constructs (Networks, Subnets, Routers) to the corresponding ACI constructs (EPG, Contracts), it will just resend (proxy) identical commands to APIC.

Read more about group-based policy at https://wiki.openstack.org/wiki/GroupBasedPolicy and the Cisco Application Policy Infrastructure Controller Driver for OpenStack Group-Based Policy Data Sheet
In few days, at the Openstack Summit in Vancouver, we'll see all the latest news about the Cisco contribution to Openstack. Don't miss it!
[Added on June 14, 2016]
You can read how easy is to start with Openstack in Why don't you try Openstack (without getting your hands dirty)?
Useful Links:
http://www.cisco.com/c/en/us/solutions/data-center-virtualization/openstack-at-cisco/index.htmlhttp://www.cisco.com/c/en/us/solutions/collateral/data-center-virtualization/application-centric-infrastructure/white-paper-c11-733126.pdf
http://specs.openstack.org/openstack/neutron-specs/specs/kilo/cisco-vpnaas-and-router-integration.html
GBP
https://www.openstack.org/summit/openstack-paris-summit-2014/session-videos/presentation/group-based-policy-extension-for-networking
http://www.cisco.com/c/en/us/solutions/collateral/data-center-virtualization/openstack-at-cisco/datasheet-c78-734181.html
https://www.rdoproject.org/Neutron_GBP







































