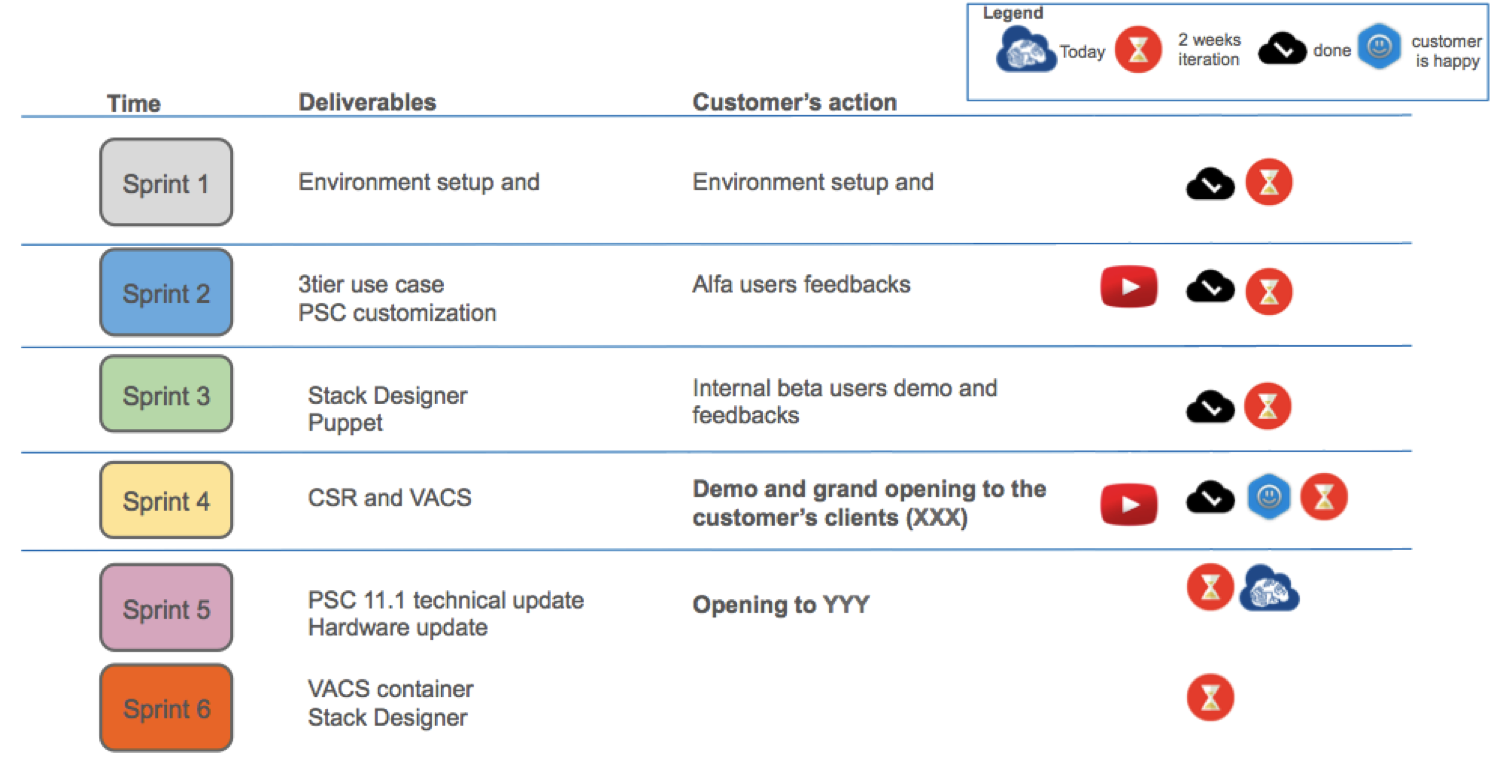
Training and real world usage of the products
Sometimes training is more focused on the procedural detail of the individual components than on the real world usage of a system.You might miss the understanding of the end-to-end architecture and the use cases that you could address with that solution so you go home, at the end of the training, without a complete awareness.
In the case of the Cisco ONE Enterprise Cloud Suite, that is composed of a number of components, in a course for beginners you will learn how to use Prime Service Catalog, UCS Director, Intercloud Fabric Director and VACS.
But, after you know how to configure them and what's the value provided by every tool, you might still wonder "what I'm going to do with this architecture?" or "how complex would it be to implement a complete project?".

I put this sample use case together to show what is the process to create a brand new service in the self service catalog, complete with all the implementation of the delivery of the service. My colleague Maxim Khavankin helped me to document all the steps.
If you download PSC and UCSD and run them with the evaluation license, you could run through this exercise very easily and make friends with the platform.
Hello World with Cisco ECS
I implemented a very simple service, just to have a context to show the implementation.No business logic is involved, or integration with back end systems, to keep you focused on the mechanics: you can easily extend this framework to your real use case.

The idea is to order a service in PSC, providing a input, and let UCSD deliver the outcome.
In our case the expected result is writing a "Hello <your name>" message in the log file.
Generally workflows in UCSD make use of tasks from the library (you have more than 2000 tasks to automate servers, network, storage and virtualization). But a specific use case might require a task that is not available already, so you build it and add it to the library.
I created a custom task in UCSD just to write to the log: of course, you could replace this extremely exciting logic with a call to the REST API - or any other API - of the system you want to target: infrastructure managers in your data center, enterprise software systems, your partner's API for a B2B service, etc.
Then I created a custom workflow in UCSD, that takes your name as a input and makes use of the task I mentioned to deliver the "Hello World" service. The workflow can be executed in UCSD (e.g. for unit testing) or invoked via the UCSD API.
Prime Service Catalog has a wizard that explores the API exposed by UCSD, discovers and imports all the entities it finds (including workflows) so that you can immediately offer them as services in the catalog for end users. Of course a customization can be added with the tools provided by PSC.
So the end to end procedure to create a business services is described by the following steps:
- Create a custom task (if required)
- Define a workflow that uses the custom task -> define input variables
- Create a catalog item in UCSD -> offer the workflow from step 2
- Synchronize PSC and UCSD
- Use the wizard to import the service in PSC
- Customize the service in the PSC catalog with Service Designer (optional)
- Order the customized service
- Check the order status on PSC side
- Check the order status and outcome in UCSD
I illustrate every step with some pictures:
Create a custom task (if required)
Custom tasks can be added to the existing library where 2000+ tasks are offered to manage servers, network, storage and virtualization.
You can group tasks in Categories so that they can be found easily in the workflow editor later.

Custom tasks can have (optional) input and output parameters, that you define based on variable types: in this case I used a generic text variable to contain the name to send greetings to:

The format, contraints and presentation style can be defined:

You can skip the steps "Custom Task Outputs" and "Controller" in the wizard to create the task: we don't need them in this use case.
Finally we create the logic for our use case: a small piece of Javascript code that executes the custom action we want to add to the automation library.
The UCSD logger object has a method to write an Information/Warning/Error message to the UCSD log file. As I wrote earlier, you could use http calls here to invoke REST API if this was a real world use case.

After you've created your custom task it's available in the automation library.
Now you have to define a workflow that uses the custom task: to pass the input that the task requires, you will define a input variable in the workflow.

The workflow is an entity that contains a number of tasks. The workflow itself has its own input and output parameters, that can be used by the individual tasks.

Input and output parameters of the workflow are defined in the same way as tasks' input and output.
They can be useful if you launch the workflow via the REST API exposed by UCSD.

Now that you've created the workflow, it's time to add some tasks to it picking from the library (exposed in the left panel of the workflow editor).
We'll only add one task (the custom task that we created): select it from the library, eventually searching for the word "hello".
Drag and drop the task in the editor canvas, then configure it.
You will see a screen similar to this one:

Configure the new task giving it a name:

Map the input variable of the task to the input parameter of the workflow that you created:

If you had not a variable holding the value for this task's input, you could still hard code the input value here (but it's not our case: this form would appear different if you hadn't mapped the variable in the previous screen).

The task does not produce any output value, so there's no option to map it to the output parameters of the workflow.

Finally we see the complete workflow (one single task, in our example) and we can validate it: it's a formal check that all the tasks are connected and all the variables assigned.



Next action is to expose this workflow to users in UCSD (in the GUI and via the API).
Create catalog item in UCSD -> offer workflow from Step 2
UCSD catalog items are offered to non-admin users if you so choose. They are grouped in folders in the user interface, and you can make them visible to specific users or groups.
You can give them a name and a description and associate a service, that could be the provisioning of a resource or a custom workflow - like in our case.

The workflow is selected and associated here:


After defining the new catalog item, you'll see it here - and in the end-user web GUI.

If the service is offered to technical users (e.g. the IT operations team), your work could be considered complete.
They can access UCSD and launch the workflow. The essential user interface of the tool is good enough for technical users that only need efficiency.
But if you're building a private cloud you might want to offer your end users a more sophisticated user interface and a complete self service catalog populated with any kind of services, where you apply the governance rules for your business.
So we'll go on and expose the "Hello World" service in Cisco Prime Service Catalog.
Synchronize PSC and UCSD
Login to PSC as admin, go to Administration -> Manage Connections.Click on the connection to UCSD (previously defined by giving it the target ip address and credentials) and click "Connect & Import".

PSC will discover all the assets offered by UCSD.
Now you can use the wizard to import the "Hello World" service in PSC. With few clicks it will be exposed in the service catalog.

The wizard allows you to associate an image and a description with the service. Here you can describe it at the level of detail and abstraction that are more appropriate for your users (or customers).
You have a full graphic editor that does not require any skills as a web designer.

Additional metadata (attributes of the service) can be added, so that users can find it when searching the catalog: there is a search engine that PSC provides out of the box.
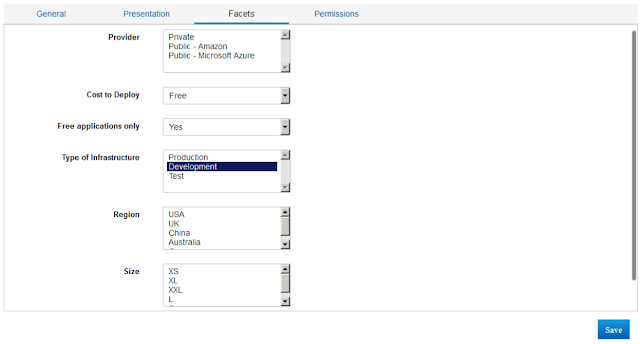
And finally you decide who can see and order the service in the catalog: you can map it to single users, groups, roles, organizations or just offer it to everyone.

At this time the service is fully working in the self service catalog and his lifecycle is managed. But, if you like, you can still apply customization and leverage the power of PSC.
Customize the service in the PSC catalog with Service Designer (optional)
There a subsystem in PSC, accessible only to specific user roles, that is called "Service Designer". It can be used to build services from scratch or to edit existing services, like the one that the wizard generated for us. Just go there and select the "Hello World" service.
The user interface of the service is built on reusable elements, that are called Active Forms (one active form could be reused in many services). The wizard generated a Active Form for our service, with a name corresponding to it.


As an example the only input field, named "person", can be transformed into a drop down list with pre-populated items. Items could even be obtained from a database query or from a call to a web service, so that the list is dynamically populated.

The power of the Service Designer offers many more customization options, but here we want to stay on the easiest side so we'll stop here :-)
Order the customized service
Go to the home page of the Service Catalog. Browse the categories (did you create a custom category or just put the Hello World service in one of the existing categories?). You can also search for it using the search function, accessed via the magnifier glass icon.In this picture you also see a review made by one of the users of the catalog that has already used the service. You can add your own after you've ordered it at least once.

You will be asked to provide the required input:

When you submit a request, your order is tracked in My Stuff -> Open Orders.
This is also used for audit activities.
Check order status on PSC side
You will see the progress of the delivery process for your order: in general it has different phases including, if needed, the approval by specific users.
Check order status and outcome in UCSD
If you go back to the admin view in UCSD (Organizations -> Service Requests) you will see that a new service request has been generated: double click on it to see the status.
if you click on the Log tab you can check the result of the execution of the service: the hello message has been delivered!
Now that you appreciated how easy is to build new services with PSC+UCSD you're ready to use all the features provided by the products and the pre-built integration that makes it very quick.
All your data center infrastructure is managed by UCSD, so that you can automate provisioning and configuration of servers, network and storage (of course, from any vendor and both physical and virtual). Once you've the automation done, offering services in the self service catalog takes just few minutes.
References
Cisco Enterprise Cloud Suite
and its individual components:
- Cisco PSC - Prime Service Catalog
- Cisco UCSD - UCS Director