In a previous post I tried to describe the new Cisco ACI architecture in simple terms, from a software designer standpoint.
My knowledge on networking is limited, compared to my colleagues at Cisco that hold CCIE certifications… I am a software guy the just understands the API ;-)
Though, now I would like to share some more technical information with the same “not for specialists” language.
You can still go to the official documentation for the detail, or look at one of the brilliant demo recorded on YouTube.
These are the main points that I want to describe:
- You don’t program the single switches, but the entire fabric (via the sw controller)
- The fabric has all active links (no spanning tree)
- Policies and performances benefit from a ASIC design that perfectly fits the SDN model
- You can manage the infrastructure as code (hence, really do DevOps)
- The APIC controller manages also L4-7 network services from 3rd parties
- Any orchestrator can drive the API of the controller
- The virtual leaf of the fabric extends into the hypervisor (AVS)
- You get immediate visibility of the Health Score for the Fabric, Tenants, Applications
Next picture shows how the fabric is build, using two types of switches: the Spines are used to scale and connect all the leaves in a non blocking fabric that ensures performances and reliability.
The Leaf switches hold the physical ports where servers are attached: both bare metal servers (i.e. running a Operating System) and virtualized servers (i.e. running ESXi, Hyper-V and KVM hypervisors).
The software controller for the fabric, named APIC, runs on a cluster of (at least) 3 dedicated physical servers and is not in the data path: so it does not affect performances and reliability of the fabric, as it could happen with other solutions on the market.
- You get immediate visibility of the Health Score for the Fabric, Tenants, Applications
Next picture shows how the fabric is build, using two types of switches: the Spines are used to scale and connect all the leaves in a non blocking fabric that ensures performances and reliability.
The Leaf switches hold the physical ports where servers are attached: both bare metal servers (i.e. running a Operating System) and virtualized servers (i.e. running ESXi, Hyper-V and KVM hypervisors).
The software controller for the fabric, named APIC, runs on a cluster of (at least) 3 dedicated physical servers and is not in the data path: so it does not affect performances and reliability of the fabric, as it could happen with other solutions on the market.

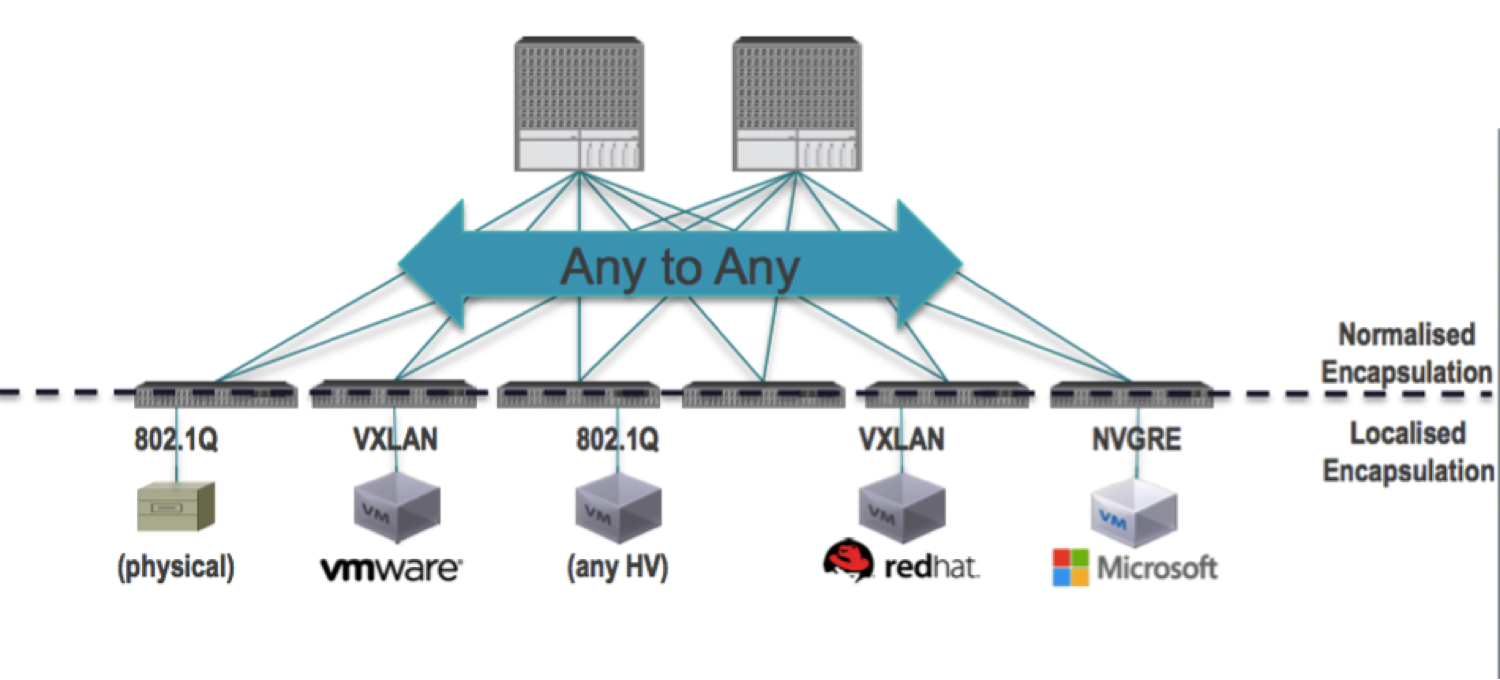
The ACI fabric decouples the endpoint identity and associated policy from the underlying forwarding graph. It provides a distributed Layer 3 gateway that ensures optimal Layer 3 and Layer 2 forwarding. The fabric supports standard bridging and routing semantics without standard location constraints (any IP address anywhere), and removes flooding requirements for the IP control plane Address Resolution Protocol (ARP) / Generic Attribute Registration Protocol (GARP). All traffic within the fabric is encapsulated within VXLAN.
The ACI fabric decouples the tenant endpoint address, its identifier, from the location of the endpoint that is defined by its locator or VXLAN tunnel endpoint (VTEP) address. The following figure shows decoupled identity and location.

You can attach virtual servers or physical servers that use any network virtualization protocol to the Leaf ports, then design the policies that define the traffic flow among them regardless the local (to the server or to its hypervisor) encapsulation.
So the fabric acts as a normalizer for the encapsulation and allows you to match different environments in a single policy.
Forwarding is not limited to nor constrained by the encapsulation type or encapsulation-specific ‘overlay’ network:
As explained in ACI for Dummies, policies are based on the concept of EPG (End Points Group).
Special EPG represent the outside network (outside the fabric, that means other networks in your datacenter or eventually the Internet or a MPLS connection):

The integration with the hypervisors is made through a bidirectional connection between the APIC controller and the element manager of the virtualization platform (vCenter, System Center VMM, Red Hat EVM...). Their API are used to create local virtual networks that are connected and integrated with the ACI fabric, so that policies are propagated to them.
The ultimate result is the creation of Port Groups, or the like of, where VM can be connected.
A Port Groups represents a EPG.
Events generated by the VM lifecycle (power on/off, vmotion...) will be sent back to APIC so that the traffic is managed accordingly.

How Policies are enforced in the fabric
The policy contains a source EPG, a destination EPG and rules known as Contracts, made of Subjects (security, QoS...). They are created in the Controller and pushed to all the leaf switches where they are enforced.When a packet arrives to a leaf, if the destination EPG is known it is processed locally.
Otherwise it is forwarded to a Spine, to reach the destination EPG through a Leaf that knows it.
There are 3 cases, and the local and global tables in the leaf are used based on the fact that the destination EP is known or not:
1 - If the target EP is known and it's local (local table) to the same leaf, it's processed locally (no traffic through the Spine).
2 - If the target EP is known and it's remote (global table) it's forwarded to the Spine to be sent to the destination VTEP, that is known.
3 - If the target EP is unknown the traffic is sent to the Spine for a proxy forwarding (that means that the Spine discovers what is the destination VTEP).

You can manage the infrastructure as code.
The fabric is stateless: this means that all the configuration/behavior can be pushed to the network through the controller's API. The definition of Contracts and EPG, of POD and Tenants, every Application Profile is a (set of) XML document that can be saved as text.Hence you can save it in the same repository as the source code of your software applications.
You can extend the DevOps pipeline that builds the application, deploys it and tests it automatically by adding a build of the required infrastructure on demand.
This means that you can use a slice of a shared infrastructure to create a environment just when it's needed and destroy it soon after, returning the resources to the pool.
You can also use this approach for Disaster Recovery, simply building a clone of the main DC if it's lost.
Any orchestrator can drive the API of the controller.
You can practice with the API, learn how to use them with any REST client and then copy the same calls into your preferred orchestrator.
Though some products have out of the box native integration with APIC (Cisco UCSD, Microsoft), any other can be used easily with the approach I described above.
See an example in The Elastic Cloud Project.
The APIC controller manages also L4-7 network services from 3rd parties.
The concept of Service Graph allows a automated and scalable L4-L7 service insertion. The fabric forwards the traffic into a Service Graph, that can be one or more service nodes pre-defined in a series, based on a routing rule. Using the service graph simplifies and scales service operation: the following pictures show the difference from a traditional management of the network services.
The same result can be achieved with the insertion of a Service Graph in the contract between two EPG:

The virtual leaf of the fabric extends into the hypervisor (AVS).
Compared to other hypervisor-based virtual switches, AVS provides cross-consistency in features, management, and control through Application Policy Infrastructure Controller (APIC), rather than through hypervisor-specific management stations. As a key component of the overall ACI framework, AVS allows for intelligent policy enforcement and optimal traffic steering for virtual applications.The AVS offers:
- Single point of management and control for both physical and virtual workloads and infrastructure
- Optimal traffic steering to application services
- Seamless workload mobility
- Support for all leading hypervisors with a consistent operational model across implementations for simplified operations in heterogeneous data centers

Cisco AVS is compatible with any upstream physical
access layer switch that complies with the Ethernet standard, including
Cisco Nexus Family switches. Cisco AVS is compatible with any server
hardware listed in the VMware Hardware Compatibility List (HCL). Cisco
AVS is a distributed virtual switch solution that is fully integrated
into the VMware virtual infrastructure, including VMware vCenter for the
virtualization administrator. This solution allows the network
administrator to configure virtual switches and port groups to establish
a consistent data center network policy.
Next picture shows a topology that includes Cisco AVS with
Cisco APIC and VMware vCenter with the Cisco Virtual Switch Update
Manager (VSUM).

Health Score
The APIC uses a policy model to combine data into a health score. Health scores can be aggregated for a variety of areas such as for infrastructure, applications, or services.The APIC supports the following health score types:
●
System—Summarizes the health of the entire network.
●
Leaf—Summarizes the health of leaf switches in the
network. Leaf health includes hardware health of the switch including fan tray,
power supply, and CPU.
●
Tenant—Summarizes the health of a tenant and the
tenant’s applications.

Health scores allow you to isolate performance issues by drilling down through the network hierarchy to isolate faults to specific managed objects (MOs). You can view network health by viewing the health of an application (by tenant) or by the health of a leaf switch (by pod).

You can subscribe to a health score to receive notifications if the health score crosses a threshold value. You can receive health score events via SNMP, email, syslog, and Cisco Call Home. This can be particularly useful for integration with 3rd party monitoring tools.
Health Score Use case:
An application administrator could subscribe to the health score of their application - and receive automatic notifications from ACI if the health of the specific application is degraded from an infrastructure point of view - truly an application-aware infrastructure.
Conclusion
I hope that these few lines were enough to show the advantage that modern network architectures can bring to your Data Center.Cisco ACI joins all the benefit of the SDN and the overlay networks with a powerful integration with the hardware fabric, so you get flexibility without losing control, visibility and performances.
One of the most important aspects is the normalization of the encapsulation, so that you can merge different network technologies (from heterogeneous virtual environments and bare metal) into a single well managed policy model.
Policies (specifically, the Application Network Policies created in APIC based on EPG and Contracts) allow a easier communication between software application designers and infrastructure managers, because they are simple to represent, create/maintain and enforce.
Now all you need is just a look at ACI Fundamentals on the Cisco web site.























